Escalabilidade
Escalabilidade é a capacidade de um sistema de se permanecer eficiente quando há um aumento significativo no número de recursos e de usuários.
— Coulouris et. al. 2008
Um sistema pode ser escalável em 3 diferentes dimensões [SDPP]:
-
tamanho;
-
localização geográfica;
-
administração.
Um sistema cujo tamanho é escalável indica que ele se mantém eficiente à medida que são adicionados mais recursos e usuários. A escalabilidade em relação à localização geográfica indica que o sistema continua funcionando, e de forma eficiente, mesmo que: a posição entre usuários e recursos mude e a distância entre eles aumente. Por fim, a escalabilidade administrativa indica que o esforço para administração do sistema ainda é baixo, mesmo com o aumento de usuários e recursos [SDPP]. Normalmente os profissionais que administram o sistema não devem perceber o impacto do aumento do tamanho.
Tornar um sistema escalável em uma ou mais dimensões é um grande desafio, uma vez que é preciso fazer um balanço entre benefícios e desvantagens. Uma das desvantagens é que o aumenta da escala para atender mais usuários pode trazer perdas de desempenho em geral [SDPP].
A partir do momento que mais computadores são adicionados para atender uma maior demanda de usuários, isto pode aumentar a troca de mensagens e o tempo de resposta, fazendo com que o desempenho geral seja reduzido. Isto ocorre principalmente quando estes computadores estão geograficamente distantes. Aumentar a escala em qualquer dimensão normalmente envolve custos adicionais, que podem ser tanto financeiros quanto operacionais. Tudo isso precisa ser levado em consideração no momento de escalar um sistema distribuído.
Problemas de Escalabilidade
Para cada uma das 3 dimensões em que um sistema pode ser escalável, existem problemas associados quando uma dessas dimensões é alterada.
Problemas de Escalabilidade de Tamanho
Quando um sistema aumenta a quantidade de usuários ou recursos, podemos ter limitações como [SDPP]:
-
serviços centralizados;
-
dados centralizados;
-
algoritmos centralizados.
Serviços Centralizados
Um serviço centralizado possui apenas um servidor para atender a todos os usuários e gerenciar todos os recursos. O problema deste modelo é que, a medida que o número de usuários ou recursos aumenta, o servidor pode ficar sobrecarregado e não conseguir atender com eficiência os usuários atuais, ou nem mesmo conseguir atender novos usuários. Assim, tal servidor pode se tornar um gargalo: um elemento do sistema que pode se tornar ineficiente com o aumento da demanda.
Figure 1. Gargalo em um sistema (Fonte: nicerweb.com).
Um exemplo claro deste problema ocorre em filas de bancos. Se há apenas um caixa atendendo os clientes, o tempo médio de espera aumenta à medida que novos clientes chegam. Em consequência, a fila tende a aumentar também, criando um círculo vicioso. Muitos usuários simplesmente deixarão de ser atendidos pois desistirão de entrar na fila ou porque o banco já não tem espaço para novos clientes. Uma solução imediata é então aumentar o número de servidores (caixas) para distribuir o atendimento.
Dados Centralizados
O problema dos dados centralizados ocorre quando o aumento na quantidade de dados traz ineficiência ao sistema. Por exemplo, se o DNS funcionasse ainda como um sistema centralizado, o tempo de busca do endereço IP para um determinado domínio teria inviabilizado a Internet ter escalado para as proporções de hoje [SDPP].
O mesmo ocorre com Sistemas Gerenciadores de Bancos de Dados (SGBDs). Em uma aplicação que possui apenas um servidor de banco de dados, tal servidor pode se tornar um gargalo com o aumento do número de usuários. Com a existência de um único servidor, os usuários podem começar a perceber lentidão de acesso em horários de pico. A situação ainda piora se, para cada usuário do sistema, uma nova conexão ao banco de dados é aberta.
Algoritmos Centralizados
Um algoritmo centralizado possui o problema de normalmente necessitar centralizar dados de diversos componentes do sistema para realizar o processamento desses dados. Por exemplo, em uma rede social como o Facebook, um algoritmo poderia ser responsável por encontrar sugestões de amizade para todos os usuários da rede. Isto exigiria que tal algoritmo obtivesse os dados e conexões (contatos) de todos os usuários mundialmente, para depois encontrar as sugestões de amizade. Considerando que a rede contabilizou mais de 1 bilhão de usuários em 2012 e 2 bilhões de acessos mensais em 2017, executar um algoritmo centralizado sobre um número tão grande de dados, sobrecarregaria recursos físicos como memória do servidor e rede (neste caso, quando os dados precisarem ser enviados para outros locais na rede). Adicionalmente, o processamento de tal volume de dados por um único servidor tornaria inviável o tempo necessário para encontrar as sugestões de amizade de todas as pessoas da rede.
Nestes casos, algoritmos decentralizados (distribuído) devem ser usados. Tais algoritmos normalmente usam a técnica Divide and Conquer (falada anteriormente) e funcionam da seguinte forma:
-
os dados são divididos em subconjuntos;
-
cada servidor recebe e processa um subconjunto de dados de forma isolada e independente;
-
os resultados de cada servidor podem ser combinados e processados novamente;
-
o resultado final é gerado.
Um modelo de programação bastante utilizado atualmente para sistemas deste tipo é o MapReduce (Mapear/Reduzir). Considere que precisamos escrever um algoritmo para contar quantas vezes cada palavra se repete em uma determinado texto. Se o tamanho do texto for pequeno, podemos fazer um algoritmo simples, utilizando um laço de repetição, que percorre todas as palavras e conta. Um algorimo deste tipo é extremamente simples e provavelmente você já fez algo semelhante em aulas de lógica de programação. Então, se o algoritmo não é complexo, o que justifica o uso de sistemas distribuídos neste caso? Se a quantidade de dados for muito grande, neste caso a quantidade de palavras, pode ser necessário criar um sistema distribuído para conseguir obter o resultado final (a quantidade de vezes que cada palavra se repete) em tempo hábil.
A figura abaixo mostra um exemplo de algoritmo distribuído utilizando o modelo MapReduce. O algoritmo então funciona em várias etapas, cada etapa sendo executada normalmente por um conjunto de computadores.
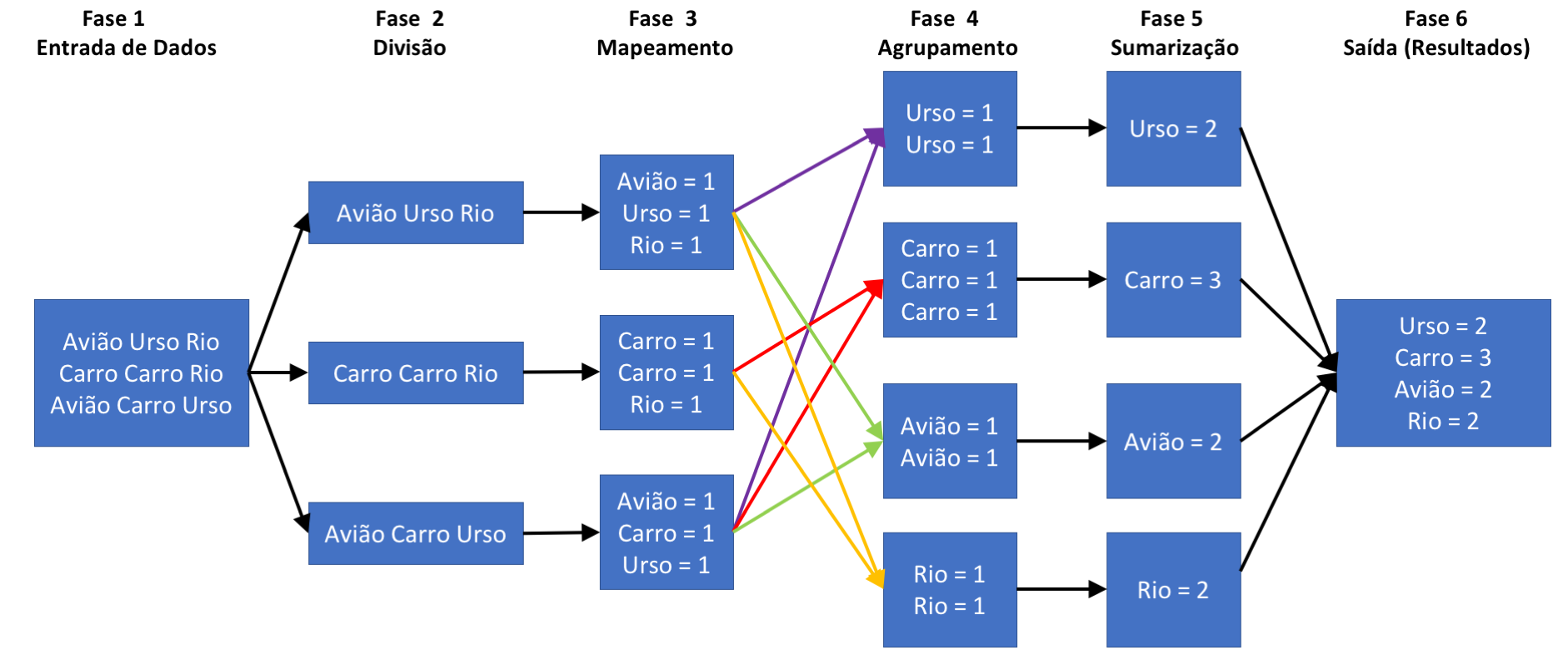
Figure 2. Contando palavras em um texto utilizando o modelo MapReduce
As etapas são apresentadas a seguir:
-
o algoritmo recebe um conjunto de dados completo (que devemos considerar que é muito grande para ser processado por uma única máquina);
-
os dados são divididos em partes que serão processadas pro aplicações executando normalmente em diferentes computadores;
-
os dados recebidos por cada processo na fase 2 são mapeados, isto é processados/transformados em fases intermediárias. Neste caso, o mapeamento é apenas a contagem das palavras recebidas por cada processo;
-
os resultados parciais então são agrupados (ordenados) para facilitar obter sub-totais;
-
a partir dos subtotais obtidos na fase anterior, tais resultados parciais são somados para obtermos os resultados finais contendo o total de vezes que cada palavra aparece no texto de entrada;
-
por fim, os totais de cada palavra são agrupados e exibidos como resultado final.
O Apache Hadoop é o framework mais popular para a construção de algoritmos seguindo o modelo MapReduce. Com o fantástico recurso de Streams do Java 8, por exemplo, tal modelo pode ser utilizada para construção de aplicações paralelas que fazem uso de vários núcleos de um processador em uma mesma máquina.
Um exemplo de contagem utilizando tal recurso do Java 8 pode ser encontrado em MapReduceApp.java. A única linha necessária para contar o total de pessoas por sexo, em paralelo, está dentro do método long contaPessoas(char sexo).
Problemas de Escalabilidade Geográfica
Antes da popularização da internet, os sistemas de uma empresa eram acessados apenas dentro da rede local (LAN). Os problemas de atraso, congestionamento e quebra de conexão eram muito menores. Usuários acessavam a aplicação por meio de uma interface desktop (instalada localmente em cada computador) ou web (por meio de um navegador).
Tais aplicações faziam requisições síncronas a um servidor dentro da rede local, onde a requisição era enviada ao servidor e a aplicação ficava bloqueada, aguardando até obter uma resposta [SDPP] [SDCP]. De fato, quando uma requisição síncrona é enviada, o thread que a executou é que fica bloqueado aguardando a resposta. Em aplicações mono-thread (que não foram projetadas para executar tarefas em paralelo), toda a aplicação fica então inoperante enquanto uma resposta não for obtida ou não ocorrer um timeout (tempo expirado).
Requisições síncronas são uma realidade em muitas aplicações web onde o usuário envia uma requisição e a aplicação fica à espera de uma resposta. Dependendo da sobrecarga e tráfego de rede, a resposta pode demorar, enquanto a aplicação fica parada à espera. Apesar dos problemas apresentados, requisições síncronas são mais fáceis de programar e o código é mais fácil de entender. Isto se deve ao fato de podermos seguir o paradigma de programação estruturada, onde instruções são executadas de forma sequencial. Dentro do código fonte de uma aplicação, pode-se, na linha imediatamente após ao envio da requisição, processar facilmente a resposta de tal requisição.
Um exemplo de tais requisições é uma aplicação web que possui um formulário cujos dados são enviados e validados do lado do servidor, como mostra o vídeo abaixo.
O usuário digita apenas parte dos dados requeridos, clica no botão "Enviar" e uma requisição é feita ao servidor. Enquanto isso o usuário deve esperar por uma resposta. O servidor verifica que os dados não foram todos preenchidos e retorna uma mensagem de erro ao cliente (navegador). O cliente então preenche os dados restantes e envia nova requisição. Uma vez que todos os dados estão corretos, o servidor envia resposta indicando que os dados foram recebidos (e possivelmente armazenados) com sucesso. No entanto, foram necessárias duas mensagens de ida e volta pela rede para finalizar o processo de envio dos dados. Durante o processo de envio da requisição, a página é recarregada e dependendo das condições da rede e sobrecarga do sistema, ela pode ficar totalmente branca até uma resposta ser obtida.
Técnicas de Escalabilidade
Para resolver os problemas de escalabilidade apresentados, podemos utilizar algumas técnicas mostradas a seguir.
Chamadas Assíncronas
As requisições assíncronas são uma solução mais eficiente para resolver o problema das requisições síncronas. Uma função assíncrona é aquela que retorna imediatamente, liberando a execução da thread. A thread é então notificada por meio de um evento, utilizando o padrão de projeto Observer, também conhecido como Event Listener. Neste modelo, o servidor irá chamar uma função no cliente para notificá-lo da resposta da requisição.
O uso de requisições assíncronas depende da linguagem de programação e bibliotecas sendo utilizadas. Tecnologias como AJAX (Asynchronous JavaScript And XML) [1, 2] e WebSockets popularizaram a utilização de chamadas assíncronas em aplicações web. Mais recentemente, Programação Reativa tem se tornado um paradigma de programação utilizado para o desenvolvimento de aplicações assíncronas em geral. Ferramentas como ReactJS, ReactiveX e Vert.x são utilizadas para este fim.
Se a linguagem utilizada não provê funções assíncronas, a criação de múltiplas threads resolve o problema do bloqueio da aplicação, pois somente a thread que fez a requisição fica aguardando uma resposta. No entanto, a criação de threads pode não ser trivial. Mesmo em linguagens como Java onde é muito simples criar threads, a construção de aplicações multi-thread que funcionem adequadamente pode ser desafiador.
Normalmente, funções assíncronas são implementadas internamente com uso de threads. A diferença é que o programador utilizando tais funções não tem que se preocupar em criar threads manualmente: elas serão criadas automaticamente quando necessário. Uma excelente fonte para entender mais como chamadas síncronas e assíncronas funcionam é o Capítulo 1 do livro JavaScript with Promises: Managing Asynchronous Code.
No entanto, nem sempre é viável utilizar chamadas síncronas, como é o caso de aplicações interativas onde o usuário não tem nada melhor a fazer do que esperar. Nestes casos, uma alternativa é mover parte do processamento para o cliente [SDPP], como é feito com validação de dados utilizando JavaScript. O vídeo abaixo demonstra esse processo.
O usuário preenche apenas parte dos dados e clica em "Enviar". Um código JavaScript executado pelo navegador informa que nem todos os dados foram preenchidos. Desta forma, a requisição não é enviada e assim temos uma resposta instantânea, uma vez que não houve troca de mensagens pela rede. Quando o usuário digita todos os dados e clica em "Enviar" novamente, o código JavaScript verifica que os dados estão corretos e só então envia a requisição para o servidor. O servidor recebe a requisição e normalmente verifica os dados mais uma vez (por questões de segurança, uma vez que o usuário pode desabilitar o JavaScript no navegador). Estando os dados corretos, o servidor responde informando que o cadastro foi realizado com sucesso. Com isto, enviamos apenas uma mensagem de ida e volta pela rede. No entanto, como podem ver no vídeo, enquanto a resposta não é obtida, a página é recarregada e normalmente fica totalmente branca até o navegador receber a resposta.
Com o uso de tecnologias como AJAX, podemos fazer a validação no lado do cliente (navegador), enviar a requisição e permitir que o usuário continue navegando enquanto a resposta não é enviada pelo servidor. O vídeo abaixo demonstra esse processo.
Observe que depois que os dados são enviados, uma outra página é exibida para o usuário poder continuar navegando. Quando a resposta é recebida uma notificação é exibida no topo de tal página.